Deployment and testing for mission-critical workloads on Azure
Failed deployments and erroneous releases are common causes for application outages. Your approach to deployment and testing plays a critical role in the overall reliability of a mission-critical application.
Deployment and testing should form the basis for all application and infrastructure operations to ensure consistent outcomes for mission-critical workloads. Be prepared to deploy weekly, daily, or more often. Design your continuous integration and continuous deployment (CI/CD) pipelines to support those goals.
The strategy should implement:
- Rigorous pre-release testing. Updates shouldn't introduce defects, vulnerabilities, or other factors that might jeopardize application health.
- Transparent deployments. It should be possible to roll out updates at any time without affecting users. Users should be able to continue their interactions with the application without interruption.
- Highly available operations. Deployment and testing processes and tools must be highly available to support overall application reliability.
- Consistent deployment processes. The same application artifacts and processes should be used to deploy the infrastructure and application code across different environments. End-to-end automation is mandatory. Manual interventions must be avoided because they can introduce reliability risks.
This design area provides recommendations on how to optimize deployment and testing processes with the goal of minimizing downtime and maintaining application health and availability.
This article is part of the Azure Well-Architected Framework mission-critical workload series. If you aren't familiar with this series, we recommend that you start with What is a mission-critical workload?.
Zero-downtime deployment
View the following video for an overview of zero-downtime deployment.
Achieving zero-downtime deployments is a fundamental goal for mission-critical applications. Your application needs to be available all day, every day, even when new releases are rolled out during business hours. Invest your efforts up front to define and plan deployment processes in order to drive key design decisions like whether to treat resources as ephemeral.
To achieve zero-downtime deployment, deploy new infrastructure next to the existing infrastructure, test it thoroughly, transition end user traffic, and only then decommission the previous infrastructure. Other practices, like the scale-unit architecture, are also key.
The Mission-Critical Online and Azure Mission-Critical Connected reference implementations illustrate this deployment approach, as shown in this diagram:
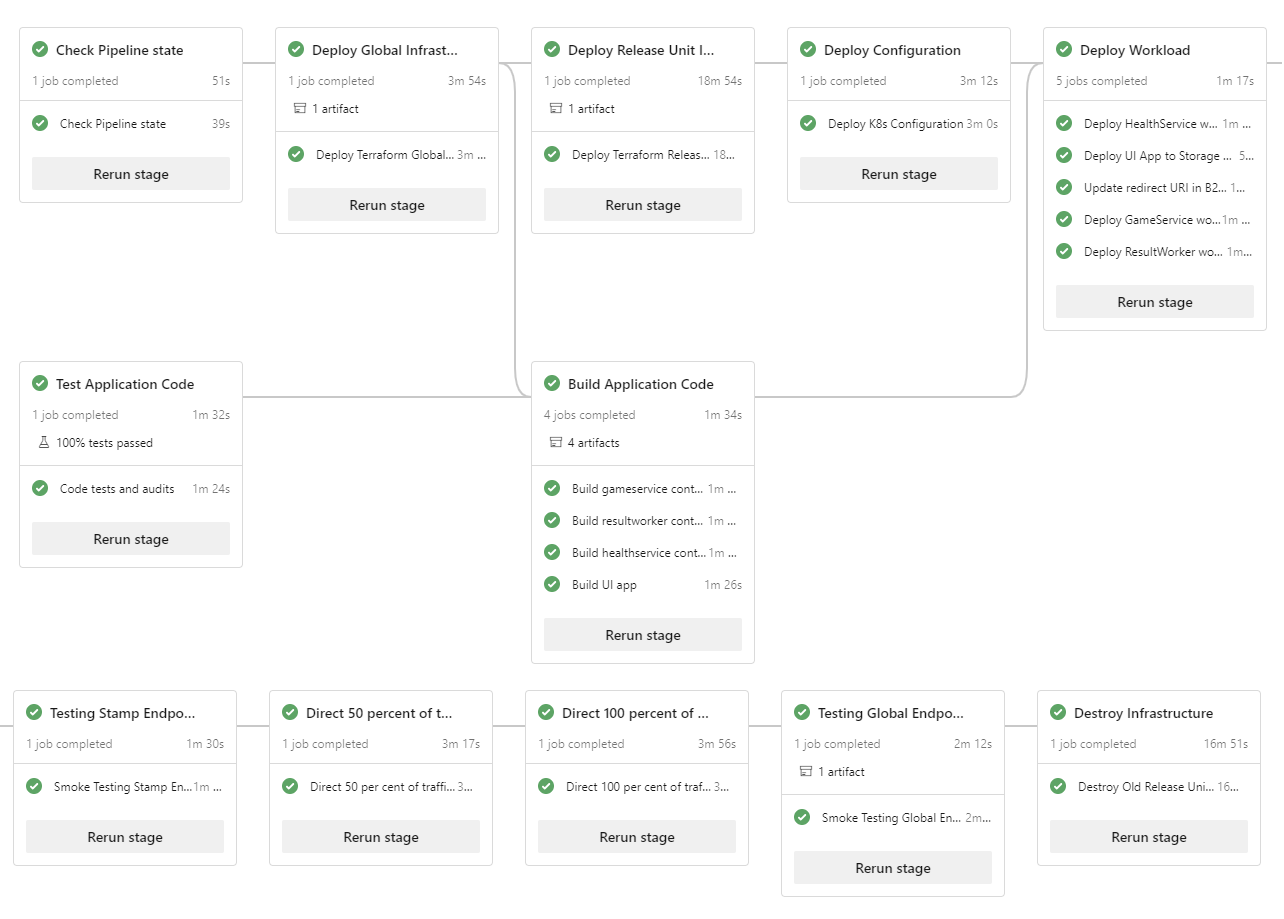
Application environments
View the following video for an overview of recommendations for application environments.
You need various types of environments to validate and stage deployment operations. The types have different capabilities and lifecycles. Some environments might reflect the production environment and be long lived, and others might be short lived and have fewer capabilities than production. Setting up these environments early in the development cycle helps to ensure agility, separation of production and preproduction assets, and thorough testing of operations before release to the production environment. All environments should reflect the production environment as much as possible, although you can apply simplifications to lower environments as needed. This diagram shows a mission-critical architecture:
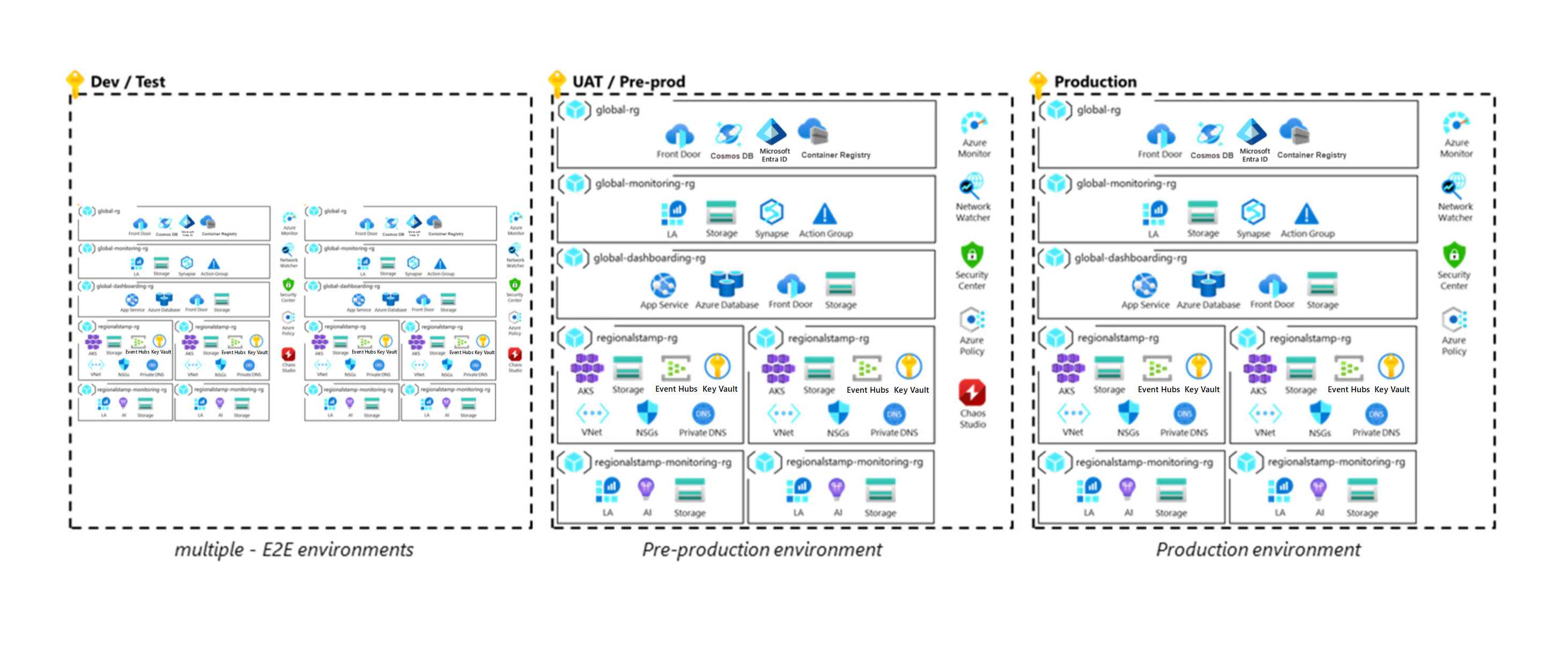
There are some common considerations:
- Components shouldn't be shared across environments. Possible exceptions are downstream security appliances like firewalls and source locations for synthetic test data.
- All environments should use infrastructure as code (IaC) artifacts like Terraform or Azure Resource Manager (ARM) templates.
Development environments
View the following video for information about ephemeral development environments and automated feature validation.
Design considerations
- Capabilities. Lower requirements for reliability, capacity, and security are acceptable for development environments.
- Lifecycle. Development environments should be created as required and exist for a short time. Shorter lifecycles help prevent configuration drift from the code base and reduce costs. Also, development environments often share the lifecycle of a feature branch.
- Density. Teams need multiple environments to support parallel feature development. They can coexist within a single subscription.
Design recommendations
- Keep the environment in a dedicated subscription with context set for development purposes.
- Use an automated process to deploy code from a feature branch to a development environment.
Test or staging environments
These environments are used for testing and validation. Many test cycles are performed to ensure bug-free deployment to production. Appropriate tests for a mission-critical workload are described in the Continuous validation and testing section.
Design considerations
- Capabilities. These environments should reflect the production environment for reliability, capacity, and security. In the absence of a production load, use a synthetic user load to provide realistic metrics and valuable health modeling input.
- Lifecycle. These environments are short lived. They should be destroyed after test validations are complete.
- Density. You can run many independent environments in one subscription. You should also consider using multiple environments, each in a dedicated subscription.
Mission-critical applications should be subjected to rigorous testing.
You can perform different test functions in a single environment, and in some cases you'll need to. For example, for chaos testing to provide meaningful results, you must first place the application under load so you can understand how the application responds to injected faults. That's why chaos testing and load testing are typically performed in parallel.
Design recommendations
- Ensure that at that least one staging environment fully reflects production to enable production-like testing and validation. Capacity within this environment can flex based on the execution of test activities.
- Generate synthetic user load to provide a realistic test case for changes on one of the environments.
Note The Mission Critical Online reference implementation provides an example of a user load generator.
Production environments
Design considerations
- Capabilities. The highest levels of reliability, capacity, and security functionality for the application are required.
- Lifecycle. While the lifecycle of the workload and the infrastructure remains the same, all data, including monitoring and logging, need special management. For example, management is required for backup and recovery.
- Density. For some applications, you might want to consider using different production environments to cater to different clients, users, or business functionalities.
Design recommendations
Have a clear governance boundary for production and lower environments. Place each environment type in a dedicated subscription to achieve that goal. This segmentation ensures that resource utilization in lower environments doesn't affect production quotas. Dedicated subscriptions also set access boundaries.
Ephemeral blue/green deployments
A blue/green deployment model requires at least two identical deployments. The blue deployment is the active one that serves user traffic in production. The green deployment is the new one that's prepared and tested to receive traffic. After the green deployment is completed and tested, traffic is gradually directed from blue to green. If the load transfer is successful, the green deployment becomes the new active deployment. The old blue deployment can then be decommissioned via a phased process. However, if there are problems in the new deployment, it can be aborted, and traffic can either remain in the old blue deployment or be redirected to it.
Azure Mission-Critical recommends a blue/green deployment approach where infrastructure and applications are deployed together as part of a deployment stamp. So rolling out a change to the infrastructure or application always results in a green deployment that contains both layers. This approach enables you to fully test and validate the effect of the change against the infrastructure and application end-to-end before you redirect user traffic to it. The approach increases confidence in releasing changes and enables zero-downtime upgrades because compatibilities with downstream dependencies like the Azure platform, resource providers, and IaC modules can be validated.
Design considerations
- Technology capabilities. Take advantage of the built-in deployment features in Azure services. For example, Azure App Service provides secondary deployment slots that can be swapped after a deployment. With Azure Kubernetes Service (AKS), you can use a separate pod deployment on each node and update the service definition.
- Deployment duration. The deployment might take longer to complete because the stamp contains the infrastructure and application rather than just the changed component. This, however, is acceptable because the risk of all components not working as expected overrides the time concerns.
- Cost impact. There's an additional cost because of the two side-by-side deployments, which must coexist until the deployment is complete.
- Traffic transition. After the new deployment is validated, traffic must be transitioned from the blue environment to the green one. This transition requires orchestration of user traffic between the environments. The transition should be fully automated.
- Lifecycle. Mission-critical deployment stamps should be considered ephemeral. Using short-lived stamps creates a fresh start each time, before resources are provisioned.
Design recommendations
- Adopt a blue/green deployment approach to release all production changes. Deploy all infrastructure and the application each time, for any type of change, to achieve a consistent state and zero downtime. Although you can reuse environments, we don't recommend it for mission-critical workloads. Treat each regional deployment stamp as ephemeral with a lifecycle that's tied to that of a single release.
- Use a global load balancer, like Azure Front Door, to orchestrate the automated transition of user traffic between the blue and green environments.
- To transition traffic, add a green back-end endpoint that uses a low traffic to volume weight, like 10 percent. After you verify that the low traffic volume on the green deployment works and provides the expected application health, gradually increase traffic. While doing so, apply a short ramp-up period to catch faults that might not immediately be apparent. After all traffic is transitioned, remove the blue back end from existing connections. For instance, remove the back end from the global load balancer service, drain queues, and detach other associations. Doing so helps to optimize the cost of maintaining secondary production infrastructure and ensure that new environments are free of configuration drift. At this point, decommission the old and now inactive blue environment. For the next deployment, repeat the process with blue and green reversed.
Subscription-scoped deployment
Depending on the scale requirements of your application, you might need multiple production subscriptions to serve as scale units.
View the following video to get an overview of recommendations for scoping subscriptions for a mission-critical application.
Design considerations
- Scalability. For high-scale application scenarios with significant volumes of traffic, design the solution to scale across multiple Azure subscriptions so that the scale limits of a single subscription don't constrain scalability.
Important The use of multiple subscriptions necessitates additional CI/CD complexity, which must be appropriately managed. Therefore, we recommend multiple subscriptions only in extreme scale scenarios, where the limits of a single subscription are likely to become a limitation.
Design recommendations
- Deploy each regional deployment stamp in a dedicated subscription to ensure that the subscription limits apply only within the context of a single deployment stamp and not across the application as a whole. Where appropriate, you might consider using multiple deployment stamps within a single region, but you should deploy them across independent subscriptions.
- Place global shared resources in a dedicated subscription to enable consistent regional subscription deployment. Avoid using a specialized deployment for the primary region.
Continuous validation and testing
Testing is a critical activity that allows you to fully validate the health of your application code and infrastructure. More specifically, testing allows you to meet your standards for reliability, performance, availability, security, quality, and scale. Testing must be well defined and applied as part of your application design and DevOps strategy. Testing is a key concern during the local developer process (the inner loop) and as a part of the complete DevOps lifecycle (the outer loop), which is when code starts on the path from release pipeline processes toward the production environment.
View the following video to get an overview of continuous validation and testing.
This section focuses on outer loop testing. It describes various types of tests.
| Test | Description |
|---|
| Unit testing | Confirms that application business logic works as expected. Validates the overall effect of code changes. |
| Smoke testing | Identifies whether infrastructure and application components are available and function as expected. Typically, only a single virtual user session is tested. The outcome should be that the system responds with expected values and behavior.
Common smoke testing scenarios include reaching the HTTPS endpoint of a web application, querying a database, and simulating a user flow in the application. |
| UI testing | Validates that application user interfaces are deployed and that user interface interactions function as expected.
You should use UI automation tools to drive automation. During a UI test, a script should mimic a realistic user scenario and complete a series of steps to execute actions and achieve an intended outcome. |
| Load testing | Validates scalability and application operation by increasing load rapidly and/or gradually until a predetermined threshold is reached. Load tests are typically designed around a particular user flow to verify that application requirements are satisfied under a defined load. |
| Stress testing | Applies activities that overload existing resources to determine solution limits and verify the system's ability to recover gracefully. The main goal is to identify potential performance bottlenecks and scale limits.
Conversely, scale down the computing resources of the system and monitor how it behaves under load and determine whether it can recover. |
| Performance testing | Combines aspects of load and stress testing to validate performance under load and establish benchmark behaviors for application operation. |
| Chaos testing | Injects artificial failures into the system to evaluate how it reacts and to validate the effectiveness of resiliency measures, operational procedures, and mitigations.
Shutting down infrastructure components, purposely degrading performance, and introducing application faults are examples of tests that can be used to verify that the application will react as expected when the scenarios actually occur. |
| Penetration testing | Ensures that an application and its environment meet the requirements of an expected security posture. The goal is to identify security vulnerabilities.
Security testing can include end-to-end software supply chain and package dependencies, with scanning and monitoring for known Common Vulnerabilities and Exposures (CVE). |
Design considerations
- Automation. Automated testing is essential to validate application or infrastructure changes in a timely and repeatable manner.
- Test order. The order in which tests are conducted is a critical consideration because of various dependencies, like the need to have a running application environment. Test duration also influences order. Tests with shorter running times should run earlier in the cycle when possible to increase testing efficiency.
- Scalability limits. Azure services have different soft and hard limits. Consider using load testing to determine whether a system risks exceeding them during the expected production load. Load testing can also be useful for setting appropriate thresholds for autoscaling. For services that don't support autoscaling, load testing can help you fine-tune automated operational procedures. Inability of system components, like active/passive network components or databases, to appropriately scale can be restrictive. Stress testing can help identify limitations.
- Failure mode analysis. Introducing faults into the application and underlying infrastructure and evaluating the effect is essential to assessing the solution's redundancy mechanisms. During this analysis, identify the risk, impact, and breadth of impact (partial or full outage). For an example analysis that was created for the Mission Critical Online reference implementation, see Outage risks of individual components.
- Monitoring. You should capture and analyze test results individually and also aggregate them to assess trends over time. You should continually evaluate test results for accuracy and coverage.
Design recommendations
View the following video to see how resiliency testing can be integrated with Azure DevOps CI/CD pipelines.
- Ensure consistency by automating all testing on infrastructure and application components. Integrate the tests in CI/CD pipelines to orchestrate and run them where applicable. For information about technology options, see DevOps tools.
- Treat all test artifacts as code. They should be maintained and version controlled along with other application code artifacts.
- Align the SLA of the test infrastructure with the SLA for deployment and testing cycles.
- Run smoke tests as part of every deployment. Also run extensive load tests along with stress and chaos tests to validate that application performance and operability is maintained.
- Use load profiles that reflect real peak usage patterns.
- Run chaos experiments and failure injection tests at the same time as load tests.
Azure Chaos Studio is a native suite of chaos experimentation tools. The tools make it easy to conduct chaos experiments and inject faults within Azure services and application components.
Chaos Studio provides built-in chaos experiments for common fault scenarios and supports custom experiments that target infrastructure and application components.
- Use Dependabot for GitHub repositories to ensure the repository is automatically up to date with the latest releases of packages and applications that it depends on.
Infrastructure as code deployments
Infrastructure as code (IaC) treats infrastructure definitions as source code that's version controlled along with other application artifacts. Using IaC promotes code consistency across environments, eliminates the risk of human error during automated deployments, and provides traceability and rollback. For blue/green deployments, the use of IaC with fully automated deployments is imperative.
A mission-critical IaC repository has two distinct definitions that are mapped to global and regional resources. For information about these types of resources, see the core architecture pattern.
Design considerations
- Repeatable infrastructure. Deploy mission-critical workloads in a way that generates the same environment every time. IaC should be the primary model.
- Automation. All deployments must be fully automated. Human processes are error prone.
Design recommendations
- Apply IaC, ensuring that all Azure resources are defined in declarative templates and maintained in a source control repository. Templates are deployed and resources are provisioned automatically from source control via CI/CD pipelines. We don't recommend the use of imperative scripts.
- Prohibit manual operations against all environments. The only exception is fully independent developer environments.
DevOps tools
The effective use of deployment tools is critical to overall reliability because DevOps processes affect the overall function and application design. For example, failover and scale operations might depend on automation that's provided by DevOps tools. Engineering teams must understand the effect of the unavailability of a deployment service with respect to the overall workload. Deployment tooling must be reliable and highly available.
Microsoft provides two Azure-native toolsets, GitHub Actions and Azure Pipelines, that can effectively deploy and manage a mission-critical application.
Design considerations
- Technology capabilities. The capabilities of GitHub and Azure DevOps overlap. You can use them together to get the best of both. A common approach is to store code repositories in GitHub.com or GitHub AE while using Azure Pipelines for deployment. Be aware of the complexity that's added when you use multiple technologies. Evaluate a rich feature set against overall reliability.
- Regional availability. In terms of maximum reliability, the dependency on a single Azure region represents an operational risk. For example, say traffic is spread over two regions: Region 1 and Region 2. Region 2 hosts the Azure DevOps tooling instance. Suppose there's an outage in Region 2 and the instance isn't available. Region 1 automatically handles all traffic and needs to deploy extra scale units to provide a good failover experience. But it won't be able to because of the Azure DevOps dependency in Region 2.
- Data replication. Data, including metadata, pipelines, and source code, should be replicated across regions.
Design recommendations
- Both technologies are hosted in a single Azure region, which might make your disaster recovery strategy restrictive. GitHub Actions is well-suited for build tasks (continuous integration) but might lack features for complex deployment tasks (continuous deployment). Given the rich feature set of Azure DevOps, we recommend it for mission-critical deployments. However, you should make a choice after you assess trade-offs.
- Define an availability SLA for deployment tooling and ensure alignment with broader application reliability requirements.
- For multi-region scenarios that use an active/passive or active/active deployment configuration, make sure that failover orchestration and scaling operations can continue to function even if the primary region hosting deployment toolsets becomes unavailable.
Branching strategy
There are many valid approaches to branching. You should choose a strategy that ensures maximum reliability. A good strategy enables parallel development, provides a clear path from development to production, and supports fast releases.
Design considerations
- Minimize access. Developers should do their work in feature/* and fix/* branches. These branches become entry points for changes. Role-based restrictions should be applied to branches as part of the branching strategy. For example, only allow administrators to create release branches or enforce naming conventions for branches.
- Accelerated process for emergencies. The branching strategy should allow hotfixes to be merged into main as soon as practical. That way, future releases contain the fix, and recurrence of the problem is avoided. Use this process only for minor changes that address urgent problems, and use it with restraint.
Design recommendations
- Prioritize the use of GitHub for source control.
Important Create a branching strategy that details feature work and releases as a minimum, and use branch policies and permissions to ensure that the strategy is appropriately enforced.
- Ensure that changes are made to main only via PRs. Use a branch policy to prohibit direct commits.
- Every time a PR is merged into main , it should automatically kick off a deployment against an integration environment.
- The main branch should be considered stable. It should be safe to create a release from main at any given time.
AI for DevOps
You can apply AIOps methodologies in CI/CD pipelines to supplement traditional testing approaches. Doing so enables detection of potential regressions or degradations and allows deployments to be preemptively stopped to prevent potential negative impacts.
Design considerations
- Volume of telemetry data. CI/CD pipelines and DevOps processes emit a wide variety of telemetry for machine learning models. The telemetry ranges from test results and deployment outcomes to operational data about test components from composite deployment stages.
- Scalability. Traditional data processing approaches like Extract, Transform, Load (ETL) might not be able to scale throughput to keep up with the growth of deployment telemetry and application observability data. You can use modern analytics approaches that don't require ETL and data movement, like data virtualization, to enable ongoing analysis by AIOps models.
- Deployment changes. Changes in deployment need to be stored for automated analysis and correlation to deployment outcomes.
Design recommendations